
IntroductionAPPLIED TECHNOLOGIES

- APPLIED TECHNOLOGIES
- LARGE VOCABULARY CONVERSATIONAL SPEECH RECOGNITION
LARGE VOCABULARY CONVERSATIONAL SPEECH RECOGNITION (LVCSR)
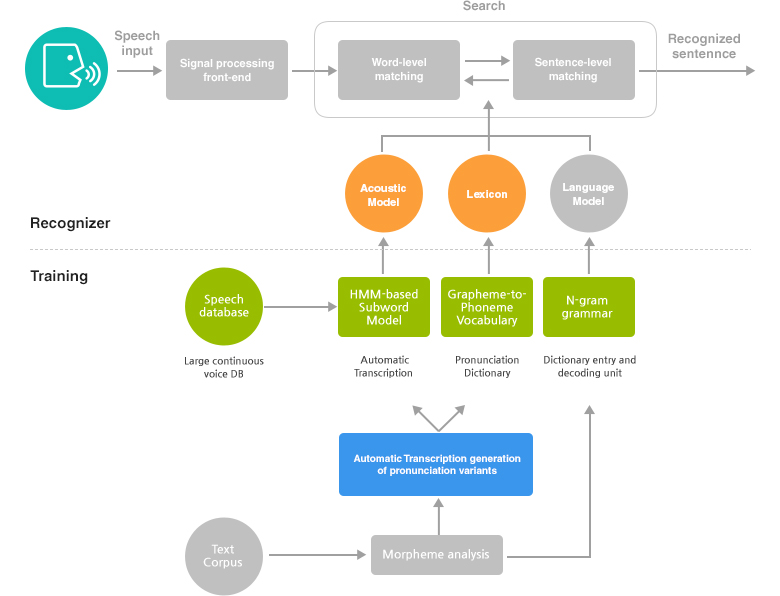
This technology recognizes the speaker's voice using an acoustic model and language model. LVCSR is comprised of a large vocabulary of around 200,000 words. Configured as a distributed voice recognition system of a server – client format, LVCSR is made up of a pre-processor, which is for signal processing and characteristic extraction, search module, which uses an acoustic model, phonetic dictionary and language model, and post-processing module.
Key algorithm
This language model using optimized language processing units to consider acoustic model reflecting phonemic changes, pronunciation generation rule algorithm, dictionary size and out-of-vocabulary is a technology to change voice to text.
- Pre-processor
- Removes noise, improves sound quality
- Extracts information from voice section
- Extracts voice characteristic parameters
- Acoustic model
- Models characteristics of voice signal that changes over time
- HMM and NN used
- Phonetic dictionary
- Automatically generates pronunciation of Korean words
- Supports multiple pronunciations
- Language model
- A grammatically correct sentence obtains a higher score as grammar between words is considered and weight is
placed on recognition candidates. - Language model is selected considering the number of target vocabularies recognized, such as FSN and
n-gram, as well as speed of recognition and recognition performance. - WFST (weighted finite-state transducer)-based decoder
- High-speed/ efficient memory management
- LM (language model) based on colloquial style n-gram specialized to smart convergence/ vehicular environment
- Post-processor
- Module to improve recognition performance or calculate reliability of recognition result by processing such
result
Technological service
Application
- CONTACT US
- COMPANY
- TECHNOLOGY
- APPLICATION
- SUPPORT&PR
Business License No.: 210-81-39168 Copyright⒞2014 POWERVOICE. All Right Reserved.